
ZFS @ catallenya-sev

This is a series of posts about my self-hosting experience. You are reading this post from this server!
In my original post about the hardware of my self-hosted server, I spoke about the possibility of an errand particle corrupting large swaths of my data.

The Veritasium channel has a good primer on the topic.
For fear of such cosmic interruptions, I shifted to a more robust, self-healing filesystem, ZFS. This filesystem helps mitigate some of the corruption risk by basically duplicating the data stored in a drive (for a mirrored setup). Here, I outline the steps I took to set up a mirrored pool, how to integrate a ZFS health notification system and also a consistent snapshot job.
Creating the ZFS pool
Fortunately for us, someone has already kindly put together an in-depth instructional on setting up ZFS on LUKS. Big shout out to the author, Andrew, for publishing the steps and making my life so much easier :)
Start by installing the ZFS tools. I'm using Ubuntu, so the instructions here are for Debian based operating systems.
sudo apt install zfsutils-linuxFor my use case, I want my ZFS drives to be encrypted. You may optionally skip these LUKS steps if you do not need encryption.
sudo cryptsetup luksFormat /dev/sda
sudo cryptsetup luksFormat /dev/sdbDecrypt the drives to setup the ZFS pool.
sudo cryptsetup luksOpen /dev/sda sda_crypt
sudo cryptsetup luksOpen /dev/sdb sdb_crypt
Create the pool, taking care to specify we want a mirrored setup. Most of the other parameters have pretty sane defaults but this website provides a good overview on what to tune.
Alternatively, the newfangled AI tools like ChatGPT are actually really good for ZFS commands. Feed your choice of parameters and the AI will give a succinct description on what they do.
sudo zpool create -f -o ashift=12 -O normalization=formD -O atime=off -m none -O compression=lz4 zpool mirror sda_crypt sdb_cryptThis completes the mirror pool. If you have encrypted the drives, the pool will be encrypted every time the machine is restarted. Since our boot drives is also encrypted, we will need to enter our master password twice - once for the boot drive and again for the ZFS pool. This is lowkey kinda cumbersome. Happily, however, the blog describes a way to create a keyfile to bring this process down to one step.
Generate a pair of binary files. Remember to lock access for these files down to root.
sudo dd if=/dev/urandom of=/root/.sda_keyfile bs=1024 count=4
sudo chmod 0400 /root/.sda_keyfile
sudo dd if=/dev/urandom of=/root/.sdb_keyfile bs=1024 count=4
sudo chmod 0400 /root/.sdb_keyfileUse LUKS to apply a keyfile. Enter the drive encryption password.
sudo cryptsetup luksAddKey /dev/sda /root/.sda_keyfile
sudo cryptsetup luksAddKey /dev/sdb /root/.sdb_keyfileRun sudo blkid to determine the ZFS pool drive. Copy the UUID. We now copy the UUID into our /etc/crypttab.
sudo nano /etc/crypttab
Add the following at the bottom of the file:
#Our new luks encrypted zpool drive credentials
#Note this gets automatically unlocked during the boot cycle
#And then it gets automatically imported into zfs and is immediately #available as a zfs zpool after the system bootup is complete.
#Add the following as one continuous line then save, quit & reboot:
sdx_crypt UUID=d75a893d-78b9-4ce0-9410-1340560e83d7 /root/.sdx_keyfile luks,discardNow when we reboot we only need to enter our password once and our ZFS pool should decrypt once we are in the OS.
Pool health notifications
With our fully functional ZFS pool, it would be wise to set up a notification system that reports the health of the pool during events. We can do this with ZED (ZFS Event Daemon), which monitors events generated by the ZFS kernel module. Crucially, ZED will log degradation events. We want to be notified when such a breakdown occurs so we can triage the errors and fix the pool before data loss occurs i.e. replacing a malfunctioning drive.
Again, it's strange to me how often there seems to be someone out there in the world who has already walked this path I am now venturing - a guide to how to implement ntfy with ZED exists! Thank you Kit, the author for publishing the steps. My post distills the instructions found in the guide for Debian based distribution.
Typically ZED comes with the scaffolding required for notifications i.e. Slack, webhooks and most recently, support for ntfy. However, certain distribution of Linux will not have the latest update for ZFS and in our case, we will need to monkey-patch the core notification changes to ZED to support ntfy.
We inspect the pull request and pull the changes required for ntfy support. This appends some new lines to two files - zed-functions.sh and zed.rc. Add those changes to your local server restart ZED. Be sure to add the correct ntfy topic, URL and token.
sudo systemctl daemon-reload
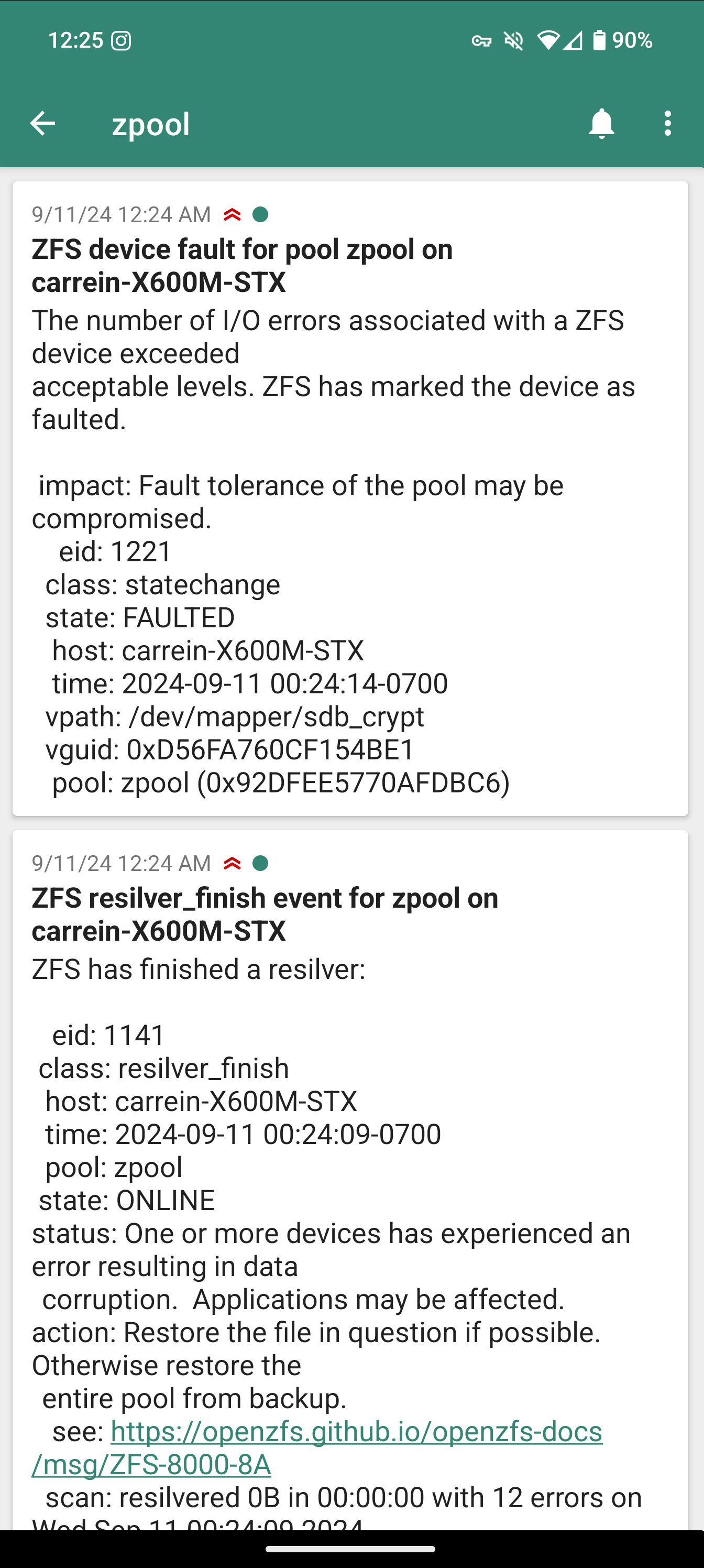
sudo systemctl restart zedTo test our ntfy system, we can simulate errors in the pool on one of our drive as described here by a ZFS contributor.
zinject -d sdb_crypt -e io -T all -f 100 zpool
Added handler 2 with the following properties:
pool: zpool
vdev: d56fa760cf154be1This should yield errors in our pool.
zpool status
pool: zpool
state: DEGRADED
status: One or more devices are faulted in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Replace the faulted device, or use 'zpool clear' to mark the device
repaired.
scan: scrub in progress since Wed Sep 11 00:24:15 2024
89.2G / 1.66T scanned at 44.6G/s, 0B / 1.66T issued
0B repaired, 0.00% done, no estimated completion time
config:
NAME STATE READ WRITE CKSUM
zpool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
sda_crypt ONLINE 0 0 72
sdb_crypt FAULTED 14 598 4 too many errorsLikewise, we should expect an associated ntfy notification of the degradation.
Once verified, we can clean up the handler and clear the fault.
zinject -c all
zpool clear zpool sdb_crypt
zpool status
pool: zpool
state: ONLINE
scan: resilvered 6.49M in 00:00:00 with 0 errors on Wed Sep 11 00:27:24 2024
config:
NAME STATE READ WRITE CKSUM
zpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sda_crypt ONLINE 0 0 0
sdb_crypt ONLINE 0 0 0
errors: No known data errorsScrubbing
With the mirrored ZFS pool, our data is replicated across two drives. To ensure data parity between these drives, we need to perform a scrub regularly. This scrubbing verifies the checksum of all data blocks across the pool and corrects any inconsistencies or errors found.
We can use the systemd service manager to initialize a weekly scrubbing operation.
[Unit]
Description=Weekly ZFS Pool Scrub
After=network-online.target
[Service]
Type=oneshot
User=root
ExecStart=zpool scrub zpoolzpool.scrub.service
[Unit]
Description=Weekly ZFS Pool Scrub Timer
[Timer]
OnCalendar=weekly
Persistent=true
[Install]
WantedBy=timers.targetzpool.scrub.timer
Enable both the timer and associated service.
systemctl enable zpool.scrub.service
systemctl enable zpool.scrub.timer
systemctl daemon-reload
systemctl start zpool.scrub timerWe can verify the timer and service are both enqueued by running systemctl list-timers --all | grep zpool.
Mon 2024-09-16 00:00:00 PDT 4 days Mon 2024-09-09 00:00:02 PDT - zpool.scrub.timer zpool.scrub.serviceAs a neat side effect, ZED will also trigger a notification on a successful scrub. This means we should ideally see a weekly ntfy notification come through with the status of our scrub operation!
Pool snapshots
Having our data more resistant to corruption is all well and good, but what do we do if the corruption does persist? With ZFS, we can perform snapshots, capturing the state of a file system at a specific point in time. This allow us to rollback our filesystem to a snapshot at a point in time, allowing us to recover from an accident.
In my system I use Sanoid to manage my snapshots.
If you are using a Debian based distribution, the build steps will fail for you. We monkey-patch a fix graciously provided by a contributor.
Once installed, we simply write a template for how often we want our snapshots to be taken.
[zpool]
use_template = production
#############################
# templates below this line #
#############################
[template_production]
frequently = 0
hourly = 24
daily = 30
monthly = 6
yearly = 1
autosnap = yessanoid.conf
Point the sanoid jobs to consume this configuration.
/usr/lib/systemd/system/sanoid.service
[Unit]
Description=Snapshot ZFS filesystems
Documentation=man:sanoid(8)
Requires=local-fs.target
After=local-fs.target
Before=sanoid-prune.service
Wants=sanoid-prune.service
ConditionFileNotEmpty=/zpool/sanoid.conf
[Service]
Type=oneshot
Environment=TZ=UTC
ExecStart=/usr/sbin/sanoid --take-snapshots --verbose --configdir /zpool/usr/lib/systemd/system/sanoid.service
[Unit]
Description=Prune ZFS snapshots
Documentation=man:sanoid(8)
Requires=local-fs.target
After=local-fs.target sanoid.service
ConditionFileNotEmpty=/zpool/sanoid.conf
[Service]
Type=oneshot
Environment=TZ=UTC
ExecStart=/usr/sbin/sanoid --prune-snapshots --verbose --configdir /zpool
[Install]
WantedBy=sanoid.service/usr/lib/systemd/system/sanoid.prune.service
Reload the daemon and verify the snapshots are being taken at our specified intervals.
sudo systemctl daemon-reload
zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
zpool@autosnap_2024-08-15_05:15:13_yearly 0B - 2.67M -
zpool@autosnap_2024-08-15_05:15:13_monthly 0B - 2.67M -
zpool@autosnap_2024-08-15_05:15:13_daily 0B - 2.67M -
zpool@autosnap_2024-08-16_00:08:04_daily 608K - 707G -
...Snapshot replication?
All the mitigation steps performed above builds us a dang good system that is much more resilient to data corruption. We now have a mirrored pool that regularly scans for data anomalies by scrubbing, issues a notification if any degradation occurs and provides us consistent snapshot to travel back in time!
There is one last piece of the puzzle that I have yet to grok a suitable solution for. The perceptive amongst you might have noticed that a truly evil particle can actually still corrupt this setup by flipping bits that are associated with our snapshots. Indeed, we would find ourselves in a situation with broken snapshots that we cannot rollback to.
We what we truly need is an off-site replication of our snapshots that we can access when our local snapshot cluster corrupts. This can be done with the ZFS commands, send/recieve. Issuing a send command creates a stream representation of a snapshot that can then be consumed by another system with the ZFS filesystem.
Therein lies the biggest caveat of setting up a ZFS replication, the off-site system itself needs to be on the ZFS filesystem. One way is to do this manually by setting up an off-site machine with ZFS installed. Yet maintaining two systems, ideally across geographical locations, is a tall order, even for me. I tried looking for a third-party vendor that provided this functionality but there really aren't many in the space, unlike file-based backup solutions i.e. Backblaze and S3. Many of the available players are either cost prohibitive, require you to ship your own drive, or have a minimum capacity order.
In theory you could potentially just stream the send output directly to a file-based cloud backup. The downside being that you kinda lose the impetus of using ZFS at all - the backed up snapshots cannot be scrubbed. If anyone has an elegant solution towards this, please let me know!



